Parsing addresses with usaddress
Last week, the Atlanta Journal Constitution (AJC) announced the first public product from our collaboration - usaddress, a python library for parsing US addresses using advanced natural language processing (NLP) methods.
 Cathy Deng
Cathy Deng
 Jeff Ersnthausen (AJC)
Jeff Ersnthausen (AJC)
Last week, the Atlanta Journal Constitution (AJC) announced the first public product from our collaboration: usaddress, a python library for parsing US addresses using advanced natural language processing (NLP) methods.
Given an address, the parser will split it into separate components with labels like street number, street name, city, and zip.
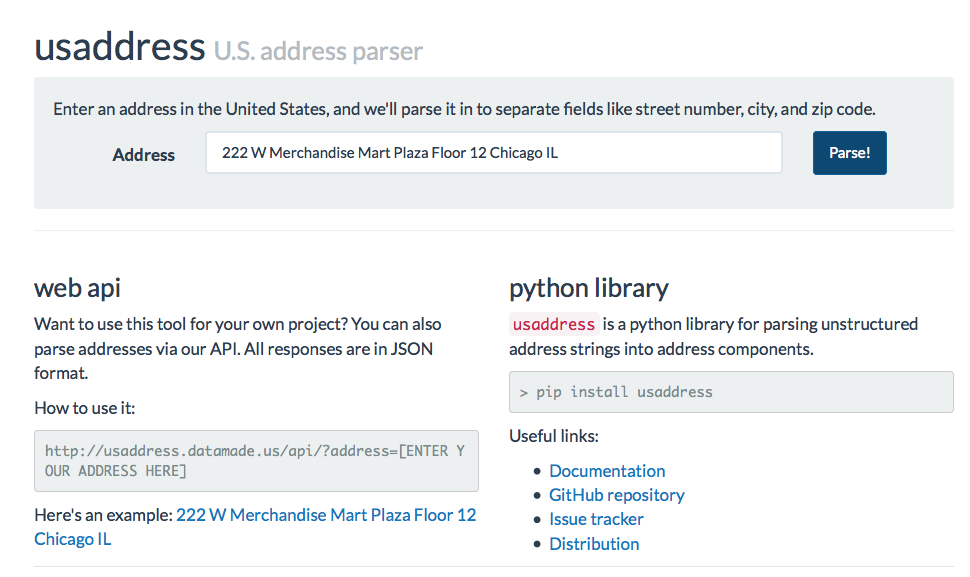
Try entering an address below!
Enter an address in the United States, and we'll parse it in to separate fields like street number, city, and zip code.
Let journalists do journalism, and computers do computation
This address parser is part of a larger project with the AJC to address the basic technical problems that prevent journalists from taking advantage of newly available government and business data.
These datasets have the potential to allow journalists to quickly and efficiently connect the dots, to reveal the influence that institutions and individuals exert on society. In other words, with the right preparation, these datasets, and the links across them, contain important stories.

To really find stories buried in data, journalists and researchers need to know that the Mr. John Smith that gave money to State Representative Roberts is the same John Smith that owns Acme Corp Limited, and that Acme Corp Limited is the same company as the Acme Corp Ltd. that got a big government contract from a committee that State Rep. Roberts sits on.
Journalists have been connecting these dots for decades, but it is slow, painstaking work. With the right tools, it can be cheaper, faster, more accurate, and automatic.
The importance of investing in data infrastructure
Addresses are one of the most common and valuable pieces of information for identifying individuals and organizations in datasets.
In order to get the most out of this important piece of information, the AJC and DataMade decided that it would be essential to break addresses into their component parts. If an address is split into those parts - like street number, street, city - it’s much easier for a computer to decide if two addresses are the same.
An address parser is an example of newsroom infrastructure. A good address parser doesn’t tell you, for example, if school bus drivers in one dataset also show up as having been convicted of DUIs in another, but tools built upon a good address parser can make such a project much more manageable.
Without an address parser, the higher level tools can’t work as well, and the news story is much harder to find.

With the AJC, we will be incorporating usaddress into a system that uses dedupe, a record linkage library we have been working on for a few years (thanks in part to some funding from Knight-Mozilla OpenNews).
We will also be developing a workflow for continuously adding and linking new data. This will allow journalists to benefit from the most timely information about public figures and organizations, and allow them to connect figures in incoming data with those already discovered in other datasets.
It can be difficult for organizations to allocate resources for infrastructure, such as usaddress, because the value is indirect and difficult to measure. However, a serious commitment to infrastructure is smart in the long run, because tools that make raw data more usable will multiply the effectiveness of everything built on top of them.
The AJC and DataMade will be sharing more about the rest of the infrastructure we are building over the next few months.
In the meantime, let’s dive into how usaddress works.
Addresses are complicated and people make mistakes
It may seem easy to split an address into its parts - after all, we do it intuitively whenever we read an address. However, a task that’s easy for humans to do is actually difficult for computers to automate - there are many valid ways of writing one address. Furthermore, real datasets are rarely free from misspellings and errors.
For example, the following addresses are composed of different characters, but it’s apparent that they all refer to the same place.
- 222 W Merchandise Mart Pl. #1200, Chicago, IL 6065
- 222 merchandise mart plaza, suite 1200, chicago, il 60654
- 222 West Merchandise Mart Plaza, Chicago, Illinois 60654
- 222 W. Merchandise Mart Plz, 12th Floor, Chicago, IL
How can we get a computer to understand what we know about addresses?
You can try making some rules
Thankfully, addresses do have a lot of structure. In American addresses, the street number usually comes first, the state is usually before the zip code, and the zip code is usually a five digit number at the end.
You can turn these regularities into programmable rules, for example: “If the beginning of an address is a number, then that number is the street number.” With a few simple rules like this, you can write a program that can accurately identify components for simple addresses that adhere to a few common patterns.
To handle cases beyond common patterns, though, you’d have to write increasingly complicated rules to handle increasingly esoteric address structures. Furthermore, human error can be nearly impossible to anticipate.
It’s difficult to model addresses with rules because rules are strict - either an address fits a rule or it doesn’t. If an address hasn’t been anticipated by rules, a rule-based parser will break down.

There’s a better way: using a statistical model
Addresses written by humans don’t have rules as much as tendencies. There is a better way of understanding addresses: a statistical approach to learn tendencies from real addresses. And that’s exactly how the usaddress parser is created.

Here’s a comparison of how CPAN Geo:StreetAddress:US, a well established rule-based parser, performs against our probabilistic parser on an example of a tricky address:
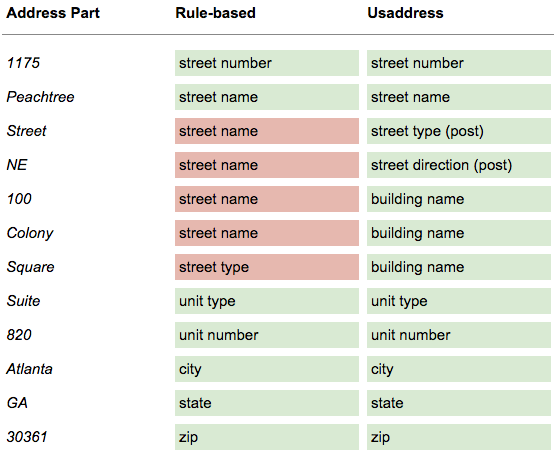
The address labels that were correct are green; the incorrect labels are red. Our parser is able to recognize that Square is a street type in some contexts, while Square is part of a building name in this particular address.
Cool! How’s it work?
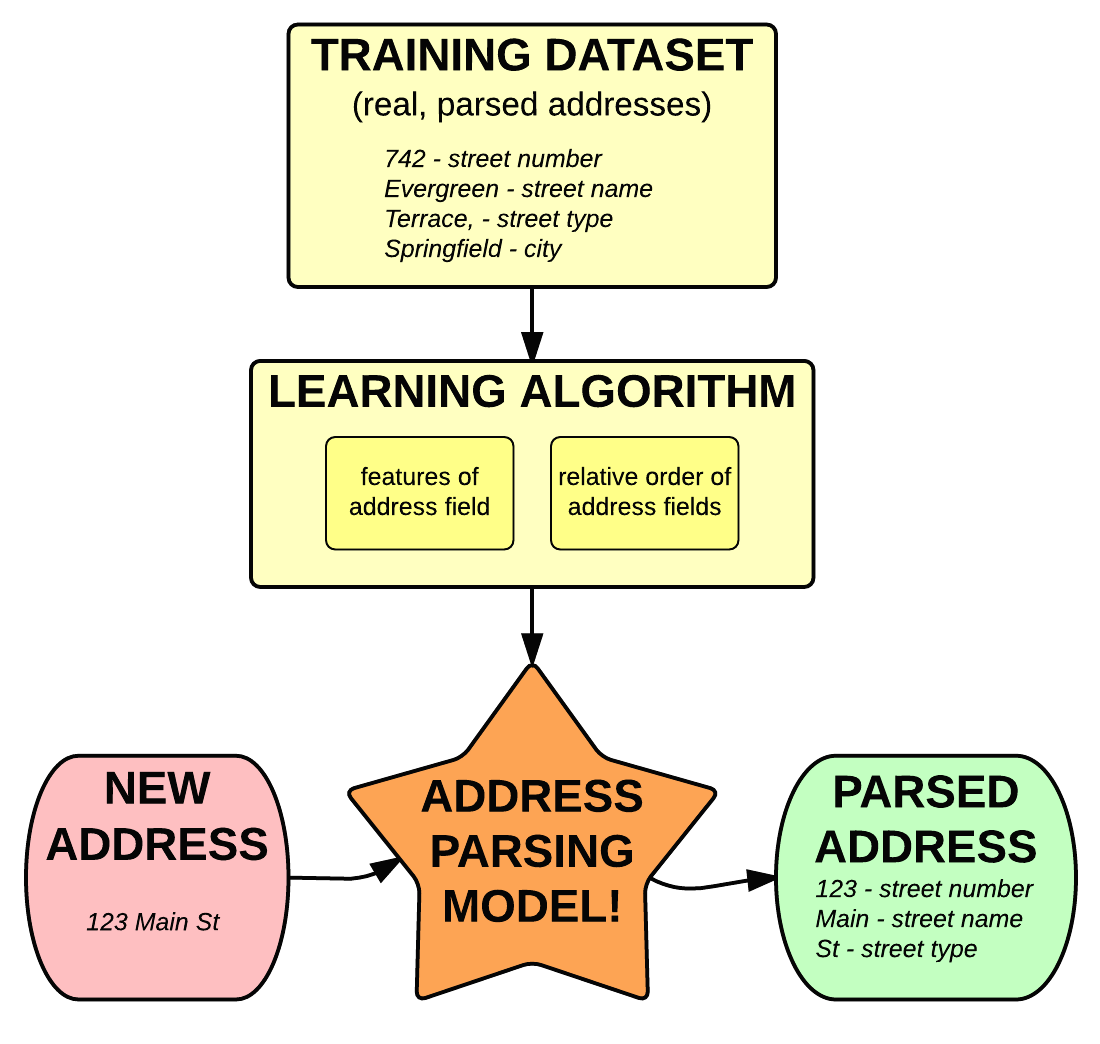
For a given address, we use a statistical model, called conditional random fields, to find the sequence of address fields that has the highest probability of generating the address.
Our model learns how to calculate these probabilities from training data - a dataset of real US addresses with address fields labeled. To calculate the most probable sequence of address fields, our learning algorithm pays attention to two things from the training data:
-
The relative order of address fields (i.e. the likelihood of neighboring address fields). For example, the model can learn that zip code often follows state
-
The features of address field content. For example, the model can learn that state is often 2 upper case letters
One neat thing about this approach is that we can continue adding addresses to our training dataset, and the model will continue to learn and improve in performance.

Using the usaddress parser
usaddress is a python library, but we made it accessible to everyone on the web, too.
For python developers:
> pip install usaddress
Then, from a python shell or script:
> import usaddress
> usaddress.parse("[ENTER YOUR ADDRESS HERE]")
For more, check out the documentation, repository and issues.
For those who just want test out some addresses:
We created a simple web interface, like the one at the top of this post to play around with parsing addresses. You can get to it at: https://parserator.datamade.us/usaddress.
Want to contribute to usaddress?
Check out the usaddress code on GitHub.
Also, if you have a dataset of messy addresses, please send them our way! The more labeled, messy addresses usaddress learns from, the better it will be.