Parse names and parse ... anything, really
Based on the success of usaddress, The Atlanta Journal-Constitution and DataMade are happy to announce two new parser tools in our collaboration: probablepeople - a parser for person names and parserator - a toolkit for making your own probabilistic, domain-specific parser.
 Jeff Ersnthausen (AJC)
Jeff Ersnthausen (AJC)
 Cathy Deng
Cathy Deng
Last October, we announced our first public product from our collaboration with DataMade: usaddress, a tool for parsing addresses using advanced natural language processing methods.
Based on the success of usaddress, The Atlanta Journal-Constitution and DataMade are happy to announce two new parser tools in our collaboration:
-
probablepeople - A parser for person names. Given a name string, split it into separate labeled components like given name, middle name and surname.
-
parserator - A toolkit for making your own probabilistic, domain-specific parser.
Let’s talk about probablepeople first.
Why are we interested in parsing names, anyways?
Whenever there are people in a dataset, there are names. However, the representation of a name can vary a great deal across different systems. For example, suppose you wanted to show all state contracts received by a “Smith” with first initial “J”.
Sometimes, John Allen Smith will write his name “John Smith,” and other times he’ll write “Smith, John Allen” or, especially in the State of Georgia, “Smith, J Allen.” He may even be listed as part a couple, like “Mary and John Smith” or “Mr and Mrs John Smith”.
Just like with addresses, the task of writing a set of rules to find all possible representations of “J. Smith” would be unwieldy due to edge cases and unanticipated formats.
probablepeople takes a probabilistic approach to parsing names based on tendencies it learns from a training set of real names. This is the same approach we used for usaddress. Read more about parsing addresses with usaddress.
probablepeople performance
Existing rule-based parsers, such as name-cleaver and nameparser, can choke upon seeing new patterns they haven’t explicitly anticipated. A probabilistic approach allows for more flexibility, and tends not to choke upon seeing new patterns.
probablepeople performs well on tricky name patterns - for example, it can parse couples, which are common in real world cases such as campaign finance. Here are some examples of tricky names that probablepeople can parse:
- Homer and Marge Simpson
- Obama, Barack H & Michelle
- Dr. Zoidberg, John A
- Ludwig Van Beethoven
- Mr West, Kanye (Yeezy)
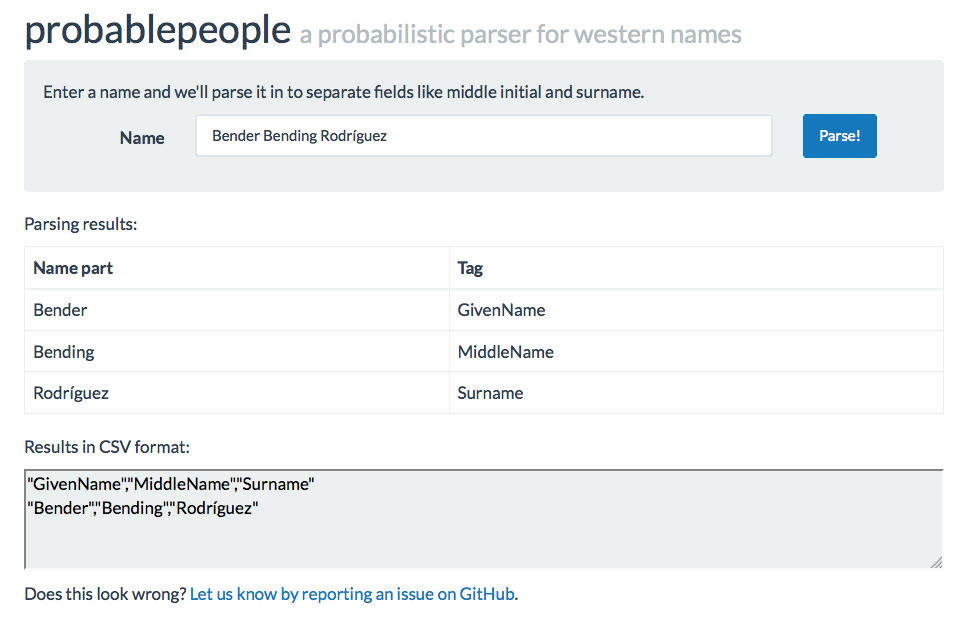
Try it for yourself below!
Enter a name, and we'll parse it in to separate fields like given name, surname and suffix.
One neat thing about a probabilistic learning approach is that the parser can continually learn and improve. If you come across names that aren’t being parsed quite right, you can teach the parser about name patterns by adding new names to the training.
Just like usaddress, as the body of contributors grows, probablepeople itself will become more robust and accurate.
Using probablepeople
For python developers:
> pip install probablepeople
Then, from a python shell or script:
> import probablepeople
> probablepeople.parse('Mr George "Gob" Bluth II')
For more, check out the repository, issues and distribution.
For those who just want test out some names:
We created a simple web interface, like the one above post to play around with parsing names. You can get to it at: http://parserator.datamade.us/probablepeople.
Parsed names and linking things
In order for journalists to take advantage of government and business data, they need to be able to identify the people, places and organizations (aka “entities”) within and across databases. Currently, we feel that this problem has no good, affordable solution for journalists or researchers.
By parsing addresses and now, names, we can extract structure from these fields — structure that wouldn’t otherwise be captured explicitly. This additional information will help us boost the signal when it comes to figuring out who’s who in different databases.

Futurama, © 20th Century Fox
We will use usaddress and probablepeople along with DataMade’s dedupe library to build an Entity-Focused Data System that can automatically and accurately link political figures, campaign filings, contracts and lobbyist disclosures.
Making your own probabilistic parser
If you’re interested in parsing something other than US addresses and western names — say, non–US addresses, or product descriptions, or citations — parserator is a toolkit for making your own probabilistic parser.

parserator is a python library, consisting of useful patterns that we abstracted from building usaddress and probablepeople. To get started, all you need is some examples of training data to teach your parser about its domain.
parserator will help you initialize a parser library, prepare your training data, and train the statistical model. For more information, see the parserator documentation, and please reach out if you have any questions!
Ultimately, probablepeople, usaddress, parserator and the Entity-Focused Data System will be part of an open source infrastructure to empower journalists to take advantage of large, messy and siloed government and business data to drive their investigations.
Now go parse some names, or better yet, make your own parser!