
Introducing Spreadsheet Deduper
Published on Mar 17, 2014
TL;DR We’re launching a free online tool for de-duplicating spreadsheets.
Data. Every day, more and more of it gets released by governments, non-profits and corporations, often for free. And that’s awesome. Each new dataset opens up important opportunities for journalists, researchers, and citizens to understand what’s going on in our world.
What’s not awesome? This data often requires a lot of cleanup before it can be useful.
The type of cleanup that we’ve found takes the most time is finding all the different records in a dataset that are really about the same thing–a task often called de-duplication. We’ve been working on building tools to make de-duplication faster and easier for everyone.
Today we are proud to announce a new tool for de-duplicating spreadsheets: Spreadsheet Deduper.
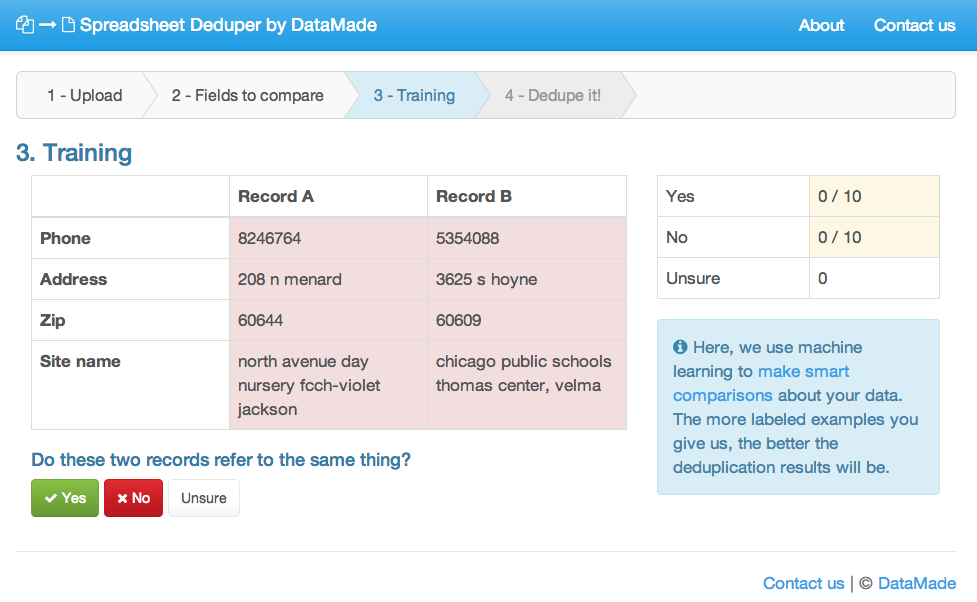 The Training step on Spreadsheet Deduper
The Training step on Spreadsheet Deduper
How it works
Spreadsheet Deduper is a web application that generically de-duplicates any spreadsheet with up to 10,000 rows in less than 5 minutes.
Here’s how it works:
- Upload a spreadsheet with up to 10,000 rows
- Choose which columns you want to compare
- Train the system by marking 20 or more positive or negative matches
- Download your original data with the duplicates identified or removed
Spreadsheet Deduper is built on top of dedupe, an open source Python library that we built to generically de-duplicate any kind of database or flat file. It builds on an entire field of academic computational research and based closely on a Ph.D. dissertation by Mikhail Yuryevich Bilenko called Learnable Similarity Functions and their Application to Record Linkage and Clustering.
The library uses some powerful string comparators, machine learning algorithms and your input to determine the best set of rules for your spreadsheet. This is the secret sauce of dedupe and Spreadsheet Deduper—you actually train the program to best identify duplicates for your spreadsheet.
Does Spreadsheet Deduper help you?
Got some messy data? Give Spreadsheet Deduper a test drive - it’s free! Does it solve your de-duplication problem? If not, send us an email and let us know why.
With Spreadsheet Deduper we are really trying to learn a few things:
- What kinds of de-duplication problems do people have?
- Is there a market for a web-based de-duplication service?
- Are there developers out there interested in building on and extending dedupe?
Also, if you want to de-duplicate data that is really big, complicated or sensitive, contact us and we can set up a custom implementation for you.
Happy de-duping!