Introducing Dedupe.io
Today, DataMade is launching something new. It’s not a map, or an app. It’s a product called dedupe.io. And it will transform your messy data into something much more useful.
Published April 28, 2016
Quickly and automatically find similar rows in a spreadsheet or database.
Today, DataMade is launching something new. It’s not a map, or an app. It’s a product called dedupe.io. And it will transform your messy data into something much more useful.
At DataMade, we build technology and use data to empower journalists, researchers, governments and advocacy organizations.
Over the course of the past four years in the civic technology space, we’ve encountered data of all kinds, including health indicators, budgets, legislation and much much more.
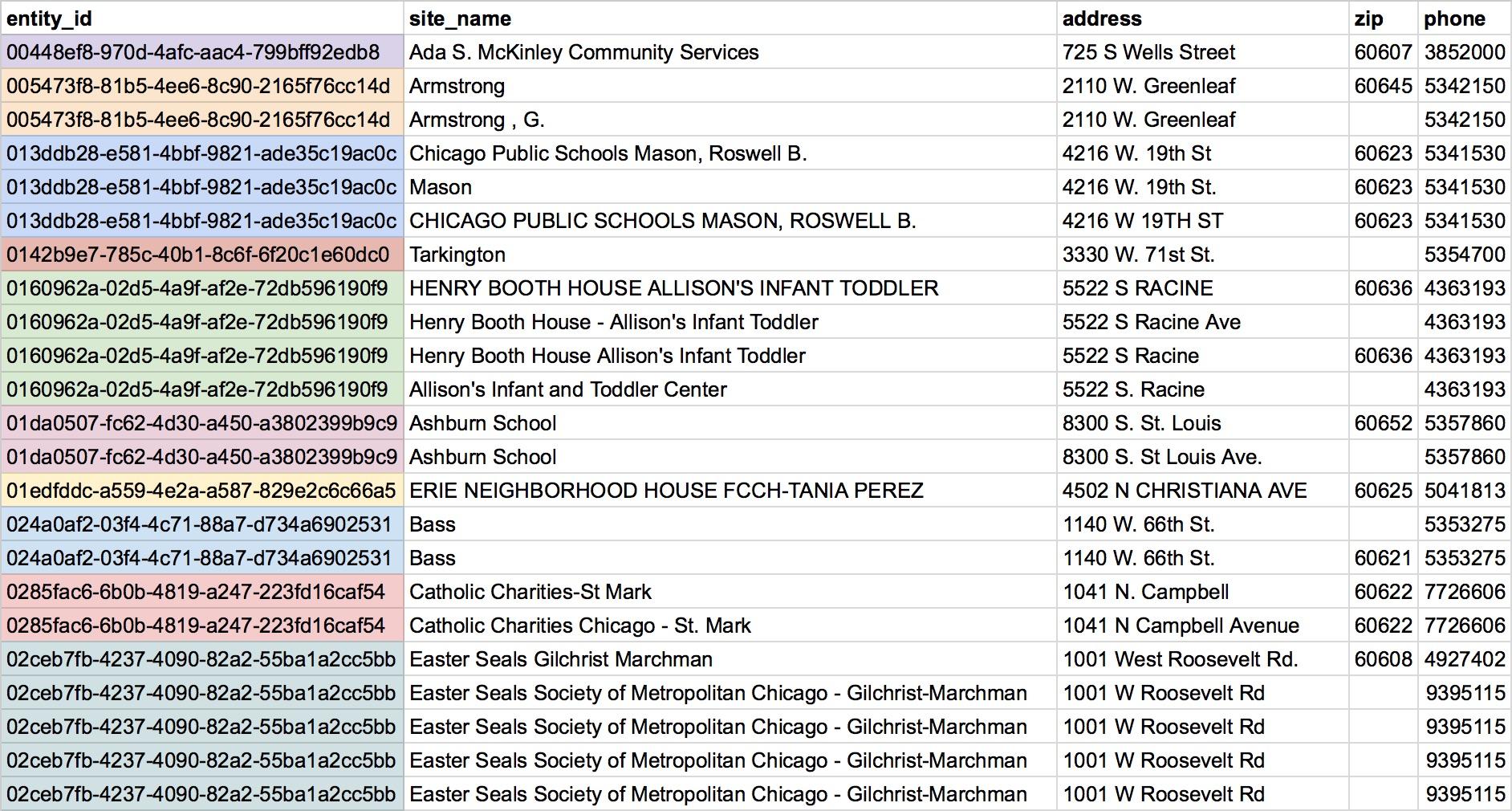
A mess of data
What do these disparate datasets have in common? There’s a lot of it, and it’s a mess.
Before we can map how much money we’re spending on incarcerating people per city block, before we can tell you how much money Ed Burke’s political campaign has in its coffers and before we can show residents what lots are for sale in their neighborhood, we have to spend a lot of time just cleaning up and preparing data. It’s a lot of work.
We know we’re not alone in this challenge. It’s why we’ve committed to releasing open source tools for working with data like usaddress, our data making guide and most notably, dedupe.
We’re very proud of these tools, and we know they’ve helped a lot. But for organizations with limited developer resources, it’s not enough. We needed to build something robust, powerful and easy to use so anyone can take advantage of these tools without the need for writing code.
A new product
That is why we are proud to be launching dedupe.io today. It’s a web interface for quickly and automatically finding similar rows in a spreadsheet or database, using machine learning methods.
Powered by our open source dedupe library, dedupe.io is customized for your data by the training you give it. From there, it learns the best way to compare records to identify duplicates in your data.
It’s built to be simple. Upload your data, provide some training examples, review some of the matches, and we take it from there.
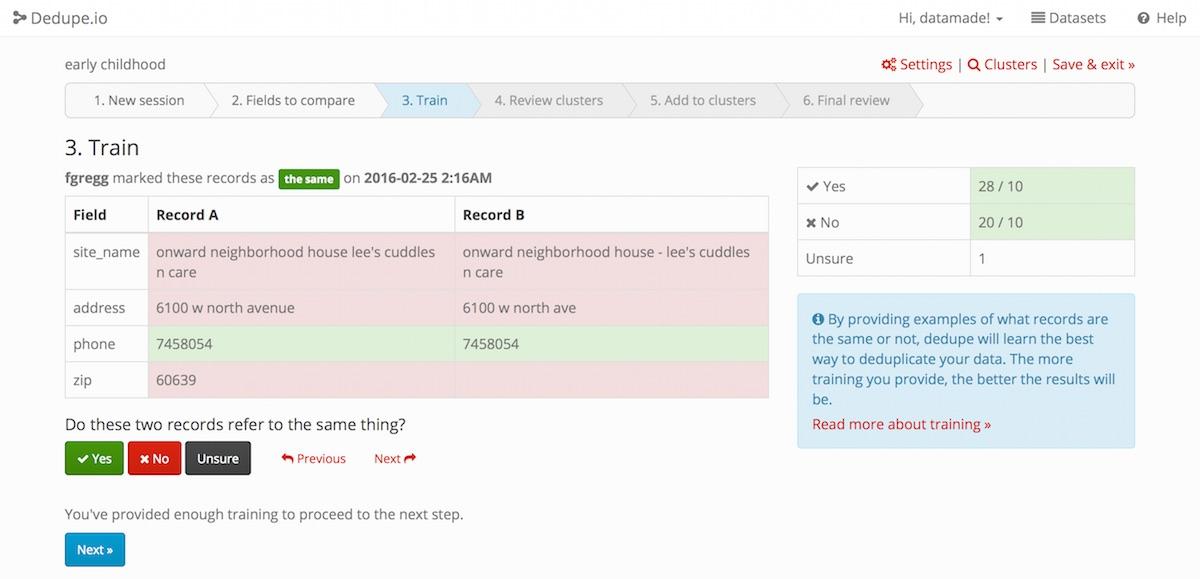
Training dedupe.io to find similar records
When it’s done you can search and review the results.
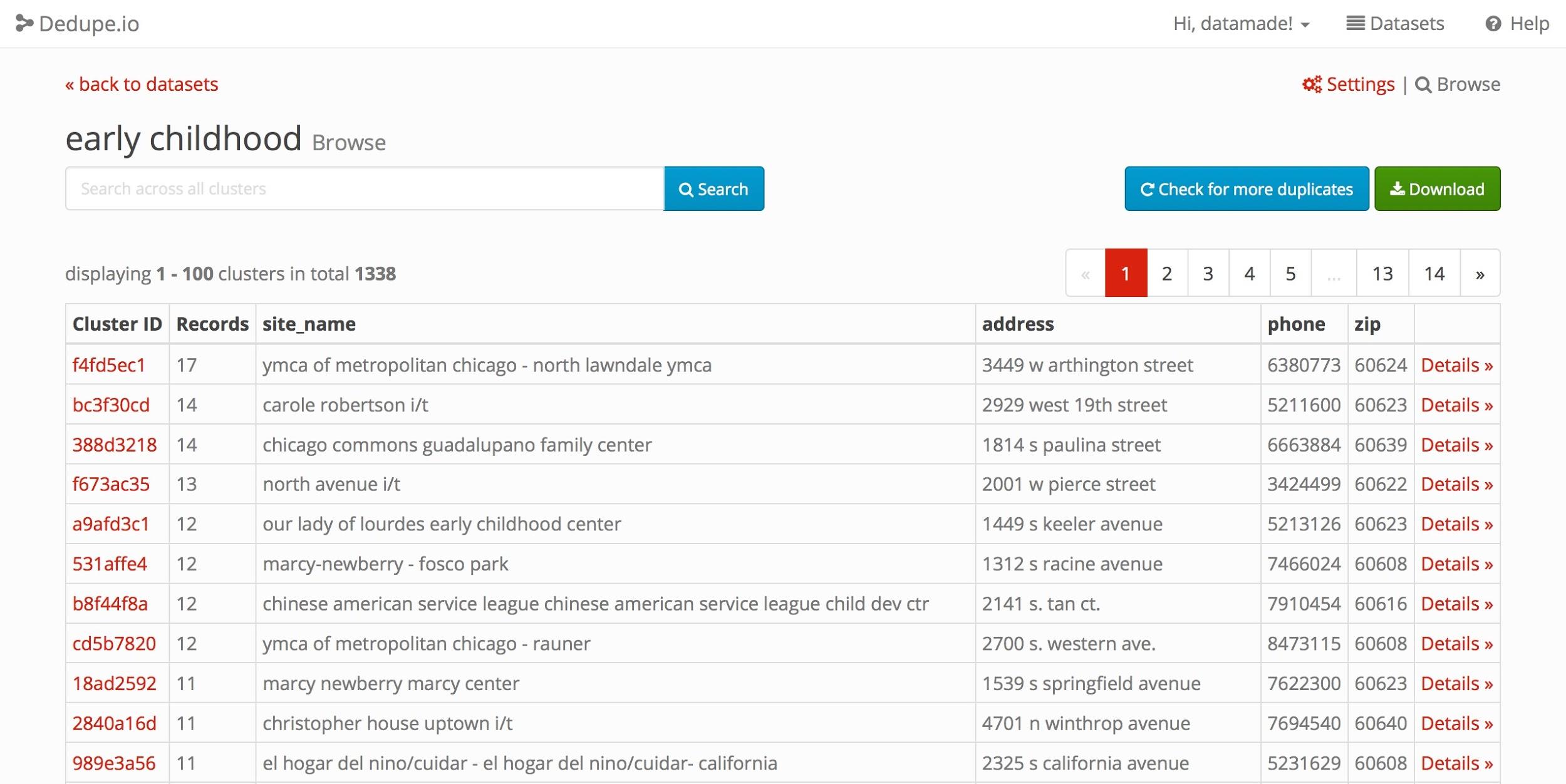
Dedupe.io results in a searchable, browseable interface
Or, you can download your original data as a spreadsheet which includes a new column called entity_id on the left that indicates a cluster of records. These results can be opened up in Excel or imported into a database.
Dedupe.io results, viewed in Excel
Additional features
Dedupe doesn’t just work on one static dataset. We’ve built it to handle a variety of data matching cases, including:
-
Record linkage - Is your data siloed in multiple systems and databases? We can link together multiple datasets and find overlapping records in each.
-
Continuous matching - Data is rarely static. New records are added and updated all the time. To handle this, we’ve set up dedupe.io to match streaming data as it comes in and apply your training to it to automatically match new records.
-
API integrations - Integrate dedupe.io seamlessly into your project or data pipeline with our restful API.
Ready to get started?
Dedupe.io is currently in private beta. If you think this tool will be useful for you or your organization, email us at dedupe@datamade.us and you can take it for a spin with your data.
You can also sign up for our newsletter to get updates and feature releases for dedupe.io.